

Komunikace skrz API
Front-end i back-end si musí mezi sebou předávat data, k čemuž slouží API – Application Programming Interface. Jednoduše řečeno, API slouží k tomu, aby šlo prvky jedné aplikace (např. čtení dat) využít jinde. Typicky najdete na spoustě stránkách tlačítko „Přihlásit se přes Google“: vývojáři si skrz API, které Google vytvořil, stáhnou informace o vás, které Google má (a zpřístupní).
Pro webové API jsou důležité HTTP metody, každá z nich se používá na něco jiného. Těmi nejdůležitějšími jsou:
- GET - slouží k získání informací ze serveru
- POST - slouží zejména k vytvoření záznamu nebo spuštění nějaké akce
- PUT - používá se na aktualizaci již existujících dat
- DELETE - odstraní danou věc
Tyto metody se od sebe, krom názvu, nijak zásadně neliší, samotná implementace je na serveru, takže když naprogramujete server tak, aby při metodě DELETE věci tvořil, je to vaše volba, ale uživatelé a ostatní lidé, co po vás ten kód budou číst nebo nedejbože používat, z toho nadšení nebudou. Proto se raději snažte držet toho, co je očekáváno, že ty metody budou dělat.
Struktura požadavku
Všechny metody kromě GET mohou serveru předat nějaké informace (tzv. tělo – body). Tělo obsahuje data čistě spjatá s daným požadavkem, např. při tvorbě záznamu v databázi to budou právě ta data, která se mají zapsat. Serveru je však třeba přidat i různé provozní informace, například v jakém formátu data jsou (text, JSON atp.), jaké sušenky má uživatel nastavené atp. K tomu slouží hlavičky (headers) a HTTP jich má definovaný nespočet. Také se liší podle toho, zda jde o hlavičku požadavku, odpovědi nebo obojí. V seznamu níže najdeš ty nejčastěji používané, pokud tě zajímají detailní informace, určitě mrkni do dokumentace.
Accept- určuje, jaký typ dat je očekáván
Content-Type- říká, jaký typ dat je právě odesílán
User-Agent- identifikuje odesílatele požadavku (např. při odesílání z prohlížeče jsou v něm detaily jako verze a typ prohlížeče)
Authorization- součástí této hlavičky jsou autorizační údaje, které požaduje server (např. když posíláš požadavek na nějakou API, co vyžaduje přihlášení nebo API klíč)
Cookie- obsahuje sušenky, které aktuálně uživatel má
Set-Cookie- vrací server, aby prohlížeč uživateli uvedené cookies nastavil
V případě GET požadavků můžeš detaily specifikovat skrz tzv. query parameter. To jsou takové ty věci, co se v URL adrese zadávají za otazník, např u YouTube videí se setkáš s query parametrem ?v=ID_VIDEA, který udává, na jaké video se vlastně chcete dívat.
Stavové kódy
Každý požadavek musí ve své odpovědi vracet číselný stavový kód. Ty se dělí na
- informační (100 - 199)
- úspěšné (200 - 299)
- přesměrovací (300 - 399)
- chybové na straně klienta (400 - 499)
- chybové na straně serveru (500 - 599)
Tyto kódy slouží k rychlému rozlišení, co vlastně nastalo za chybu během zpracování požadavku. Např. když dostaneš chybu s kódem 400, budeš vědět, že jsi někde ve svém kódu udělal chybu, která se serveru nelíbila, jelikož tento kód znamená Bad Request - špatný požadavek. Implementace však opět záleží na serveru, proto doporučuji prohlédnout si dokumentaci, nebo si prohlédnout zjednodušený přehled nejpoužívanějších kódů ve formě koček.
Ukázka typické API
Řekněme, že máme informační systém v knihovně. Tato knihovna chce spolupracovat s jinými knihovnami, navzájem si doplňovat informace atp. Pro základní CRUD (Create, Read, Update, Delete – Tvorba, čtení, změna, odstranění) operace nad databází knih proto vytvoří následující koncové body (endpointy):
GET /book
POST /book
GET /book/:idKnihy
PUT /book/:idKnihy
DELETE /book/:idKnihyVšimni si, že jsem u posledních tří endpointů použil zápis :nazev, tímto jsem zapsal tzv. path parameter (volně přeloženo “parametr v cestě”). Ve stručnosti se jedná o to, že pokud chceme pracovat s dynamickým obsahem, například s různými knihami, nemusíme při každém požadavku oznamovat, s jakým ID chceme pracovat. Místo toho stačí vytvořit jednu logiku, ve které jen získáme danou věc (zde ID knihy) z cesty požadavku.
V tomto případě proto můžeme zjednodušit logiku a strukturu API tak, že
/bookslouží pro práci s celým souborem knihGETtedy vrátí všechny knihy v databázi
POSTvytvoří novou knihu
- na
/book/:idKnihypůjdou všechny požadavky týkající se specifické knihyGET,PUTaDELETEbudou získávat, měnit a mazat tu knihu, kterou uvedeme v cestě požadavku
Dokumentace API pomocí OpenAPI
Psát dokumentaci je zdlouhavý proces a z předchozí sekce jsi určitě příliš nezmoudřel. Přesně proto vymyslely chytré hlavy specifikaci s názvem OpenAPI, která určuje, jak ve strojově čitelném formátu popisovat funkce jednotlivých částí webových API. S tímto souborem pak mohou pracovat jiné nástroje, např. si můžete dokumentaci nechat vypsat v uživatelsky přívětivém formátu skrz Scalar, nebo si vygenerovat hotového API klienta. Schválně si prohlédni schéma, které jsem vytvořil pro API knihovny z předchozí části. Jako čistý JSON ti to nejspíš nic moc neřekne, když ho ale nahraješ do Scalaru, vypíše ti všechno, co potřebuješ vědět: jaké API endpointy jsou dostupné, co vrací a s jakým stavovým kódem.
Mé ukázkové schéma je velice minimální, dá se tam přidat spousta dalších věcí, jako textové popisy jednotlivých endpointů, více stavových kódů, definice bezpečnostních prvků (např. kontrolování zmíněné Authorization hlavičky). Vytváření schématu API je proto velmi důležité, zejména když chceš API nabízet někomu, kdo není s tvým kódem obeznámen. Navíc spousta webových frameworků už umí toto schéma generovat samo, takže ti ušetří spoustu práce.
Server-sent events: hromadné zasílání dat vícero klientům
SSE se hodí v případech, kdy chceš hromadně poslat nějakou informaci. Třeba kdybys měl stránku s chatem, můžeš použít SSE, abys všem připojeným uživatelům poslal oznámení o nové zprávě.
Práce s SSE je snadná: stačí mít server (vysílač) a nějaký počet klientů (přijímačů). Server může posílat zprávy, nebo si nadefinovat vlastní typ události, kterou pak klient bude poslouchat. Klient samozřejmě může poslouchat více událostí naráz.
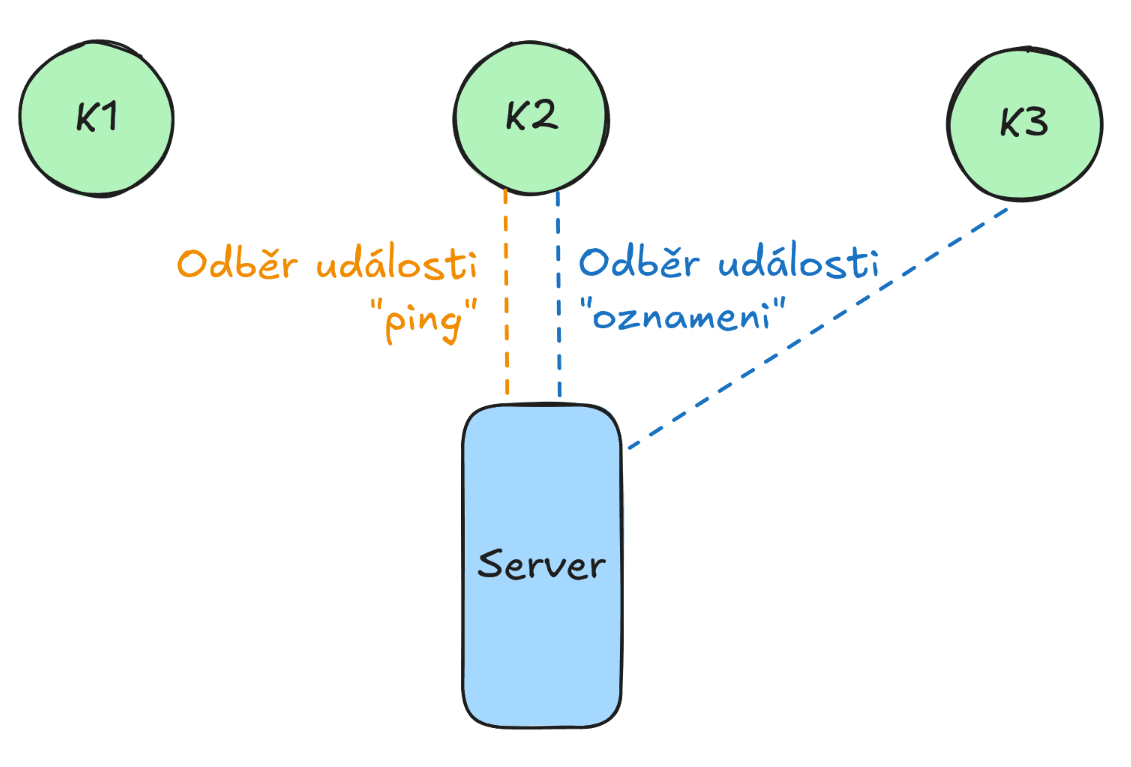
Odeslání události musí server vyvolat sám, zde se může nabízet odeslání události s názvem oznameni v případě, kdy uživatel vytvoří novou zprávu.
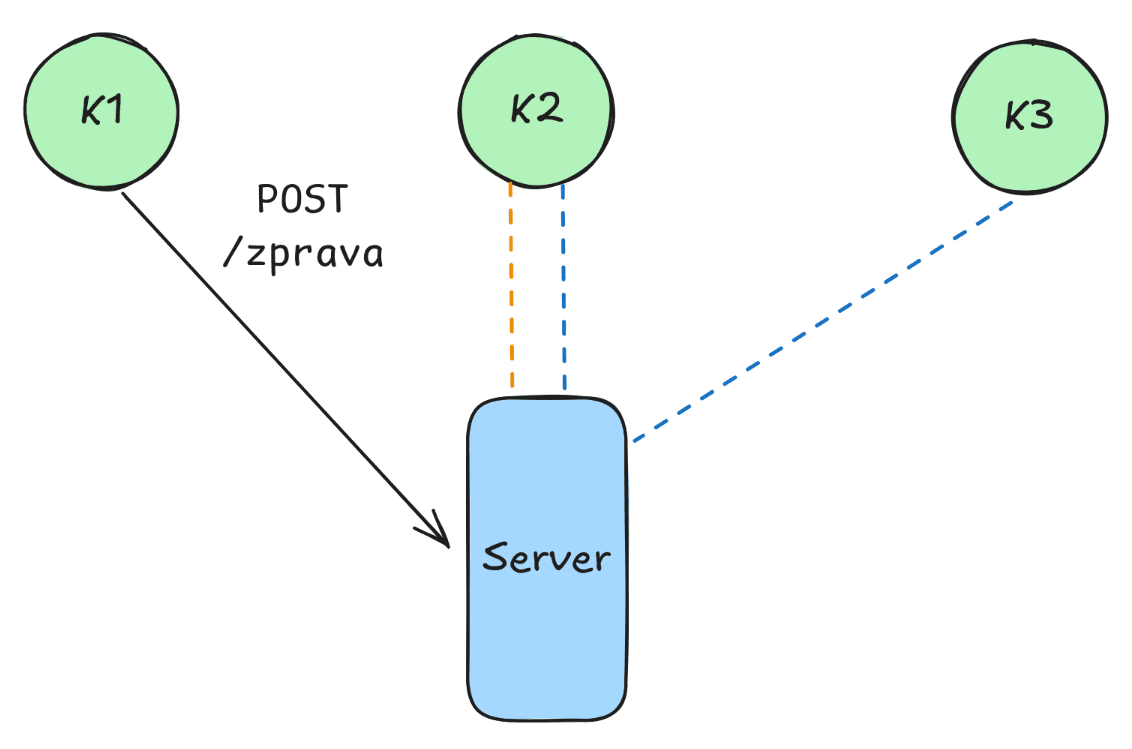
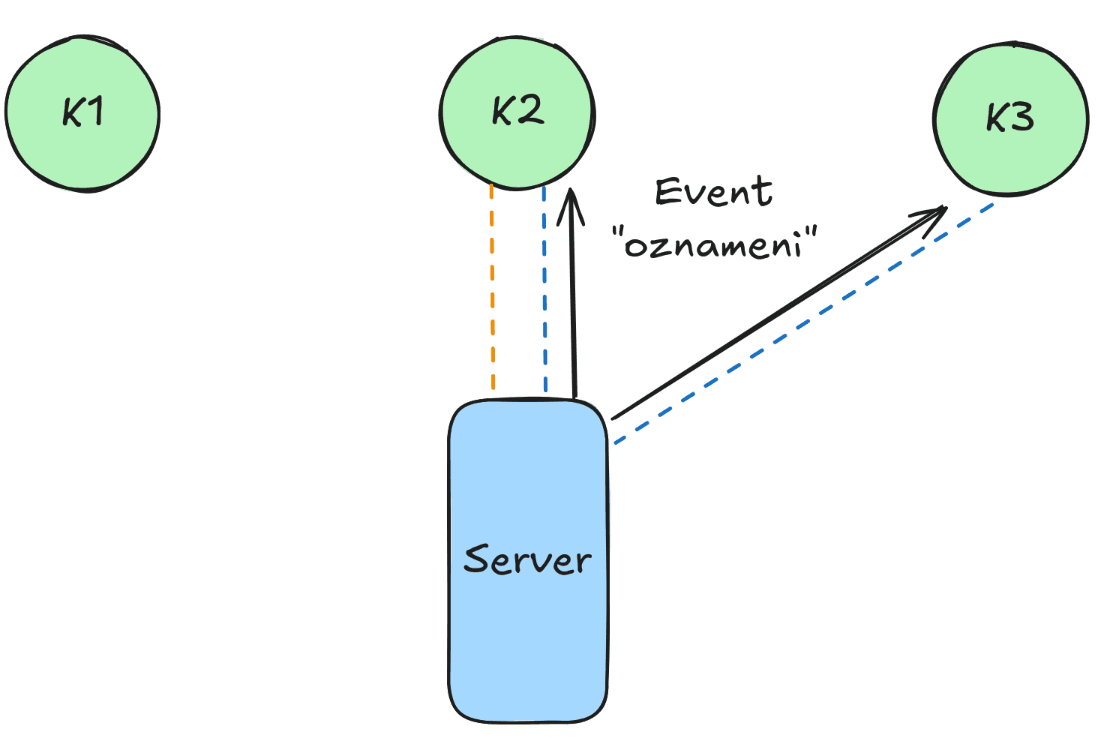
Server teď pošle událost oznameni všem napojeným klientům. Pokud zrovna odebírají tuto událost, můžou s ní dále pracovat ve svém kódu. Narozdíl od HTTP požadavků jsou SSE jednosměrné, klient tedy při přijetí události nemůže serveru odpovědět.
© 2025 Student Cyber Games, z.s. – Vydáno pod licencí CC BY-NC-SA 4.0.